
Intelligent-Product-Pitch-Recommendation-System.
An AI-powered system that generates personalized product pitches by analyzing customer context and intent. It helps businesses move from…
Next.jsTypeScriptSupabasePostgreSQL+2
Loading…
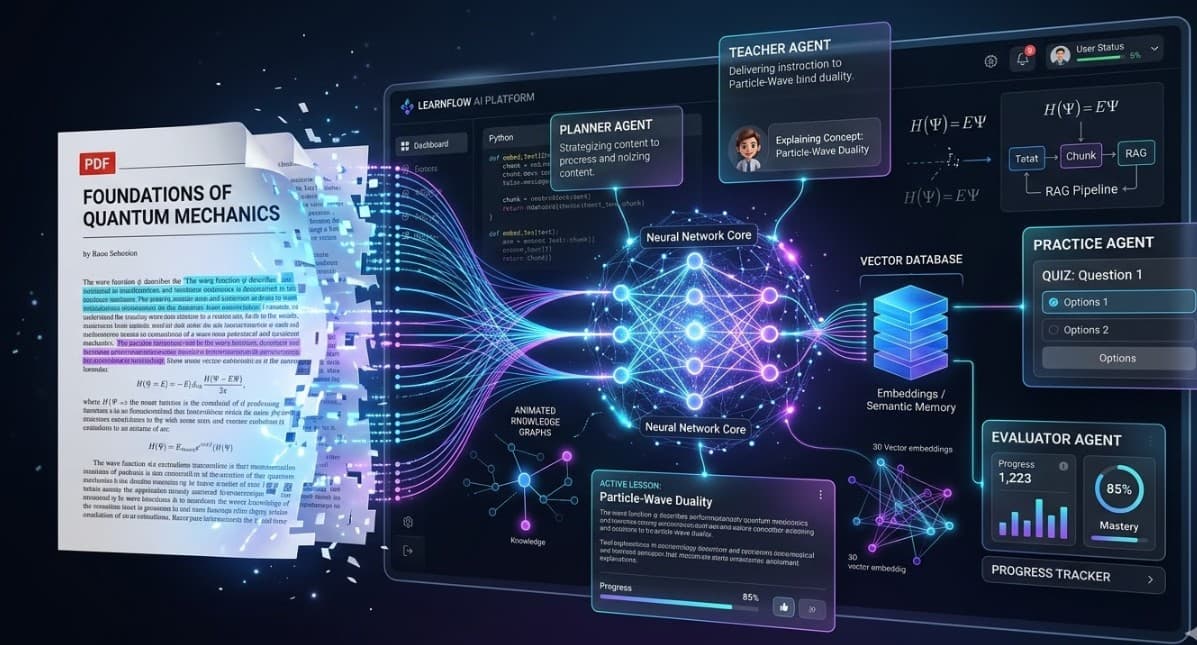
MeroStudySathy is an AI-powered learning system that transforms static PDF documents into interactive, guided learning experiences.
Instead of passively reading long documents, users receive a structured study plan, AI-guided explanations, practice questions, and detailed feedback — all generated directly from the uploaded material.
The system uses a multi-agent architecture where specialized AI agents collaborate to analyze documents, teach concepts, generate practice problems, and evaluate answers.
• Multi-agent architecture (Planner, Teacher, Practice, Evaluator)
• Retrieval-Augmented Generation (RAG) pipeline
• Vector search using document embeddings
• AI-generated structured study plans
• Interactive teaching sessions with document citations
• Automatic practice question generation
• Answer evaluation with feedback and scoring
• Weak topic detection and progress tracking
• Response caching to reduce repeated API costs
The system follows a local-first Retrieval-Augmented Generation (RAG) architecture where documents are processed, indexed, and taught through specialized AI agents.
┌─────────────────────────────────────────────────────────────────┐
│ YOUR PDF DOCUMENT │
└────────────────────────────┬────────────────────────────────────┘
│
▼
┌────────────────┐
│ PDF EXTRACTION │
│ (per-page) │
└────────┬───────┘
│
▼
┌────────────────┐
│ TEXT CHUNKING │
│ 1000 tok/150 │
└────────┬───────┘
│
▼
┌────────────────┐
│ EMBEDDINGS │
│ (batch: 100) │
└────────┬───────┘
│
▼
┌────────────────────────┐
│ SQLITE VECTOR STORE │ ←── Response Cache Layer
│ (local database) │ (0 API cost on repeat)
└───────────┬────────────┘
│
┌───────────────────┼───────────────────┐
│ │ │
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ PLANNER │ │ TEACHER │ │PRACTICE │
│ AGENT │ │ AGENT │ │ AGENT │
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
▼ ▼ ▼
Learning Plan Teaching Sessions Quiz Questions
(structured) (with citations) (with feedback)
│ │ │
└──────────────────┼───────────────────┘
│
▼
┌─────────────┐
│ EVALUATOR │
│ AGENT │
└──────┬──────┘
│
▼
Progress Tracking
Weak Topic Identification
All documents, embeddings, and response caches are stored locally in a SQLite database, ensuring privacy while significantly reducing API costs through response caching.
Most study tools only highlight or summarize text. I wanted to build something closer to a real tutor — a system that understands a document and teaches it interactively.
This project explores AI agent collaboration, retrieval systems, and educational workflows to make self-learning more effective.
Identified the limitations of traditional PDF-based studying and designed a system to convert static documents into interactive AI tutoring sessions.
Built the document processing pipeline including PDF extraction, semantic chunking, embeddings generation, and vector search using SQLite.
Implemented Planner, Teacher, Practice, and Evaluator agents to simulate a real tutoring workflow.
Developed a real-time teaching interface with streaming responses, source citations, and follow-up questioning.
Added automated answer evaluation, scoring, and weak topic detection to track learning progress.
An AI-powered system that generates personalized product pitches by analyzing customer context and intent. It helps businesses move from…


An MCP server that gives Claude full natural-language control over any REST CMS — 32 auto-generated tools, human approval gate, policy…